Emulation und Migration helfen, den authentischen Zustand von Dateien im Webarchiv zu erhalten und sie in zukünftigen Umgebungen zugänglich zu machen.
Autor*innen: Karin Heide BA, Mag. Andreas Predikaka
"‘Langzeit‘ bedeutet für die Bestandserhaltung digitaler Ressourcen nicht die Abgabe einer Garantieerklärung über fünf oder fünfzig Jahre, sondern die verantwortliche Entwicklung von Strategien, die den beständigen, vom Informationsmarkt verursachten Wandel bewältigen können.“ 1
Die Anfänge der digitalen Langzeitarchivierung (LZA) liegen nun bereits mehr als ein halbes Jahrhundert zurück4 und sind eng verbunden mit der Entwicklung der elektronischen Datenverarbeitung in den späten 1960er und frühen 1970er Jahren. Ab den 1980er Jahren lieferte vor allem die Raumfahrtforschung wesentliche Impulse zur Verwaltung und Bereitstellung großer Datenmengen.3
Die Entwicklung des Internets und das damit verbundene Aufkommen neuer elektronischer Publikationsstrukturen ab den 1990er Jahren führte schließlich dazu, dass sich auch die Bibliotheks- und Archivwissenschaften verstärkt mit dem Thema der digitalen LZA auseinanderzusetzen begannen. Die Entwicklung internationaler Standards und einer Terminologie für digitale Objekte und die mit ihnen assoziierten Metadaten ist eine Folge dieser interdisziplinären Zusammenarbeit. Auch die Entwicklung des Open Archival Information System (OAIS) als international anerkanntes funktionales Referenzsystem fällt in diesen Zeitraum.4
Weltweit setzen sich Bibliotheken, Archive, Gedächtnis- und Forschungsinstitutionen also bereits seit mehreren Jahrzehnten theoretisch und praktisch mit dem Thema der digitalen LZA auseinander. Und auch im Allgemeinverständnis ist der Begriff der Backup-Kopie längst angekommen. Es stellt sich also die Frage:
Das komplexe Feld der digitalen LZA gliedert sich in zwei große Aufgabenbereiche:
Die nestor-Arbeitsgruppe Standards für Metadaten schreibt dazu, dass "Daten […] aus üblicherweise heterogenen technischen und organisatorischen Kontexten so übernommen werden [müssen], dass sie trotzdem in ganz anderen, zukünftigen Kontexten verstehbar und nutzbar sein werden.“5
Die hier unter Punkt 1 angeführte „Sicherung der Daten“ wird als Bitstream Preservation bezeichnet und meint das, was allgemein unter Archivkopie oder Backup verstanden wird. Für ein präziseres Verständnis der großen Herausforderung, mit der alle langzeitarchivierenden Institutionen konfrontiert sind, ist es notwendig, sich den Punkt 2 der Aufgabenbereiche näher anzusehen.
Im Sinne einer Begriffsklärung lässt sich sagen:
Digitale LZA muss sich nicht nur mit der Sicherung der Datenströme, sondern auch mit der Sicherung des Zugriffs (Access) und somit mit allen denkbaren zukünftigen Nachnutzungsszenarien auseinandersetzen.
Letztlich umreißt bereits der Begriff „Datenstrom“ (Bitstream) worum es in bei der Konzeption und praktischen Umsetzung eines vertrauenswürdigen digitalen Langzeitarchivs6 gehen muss:
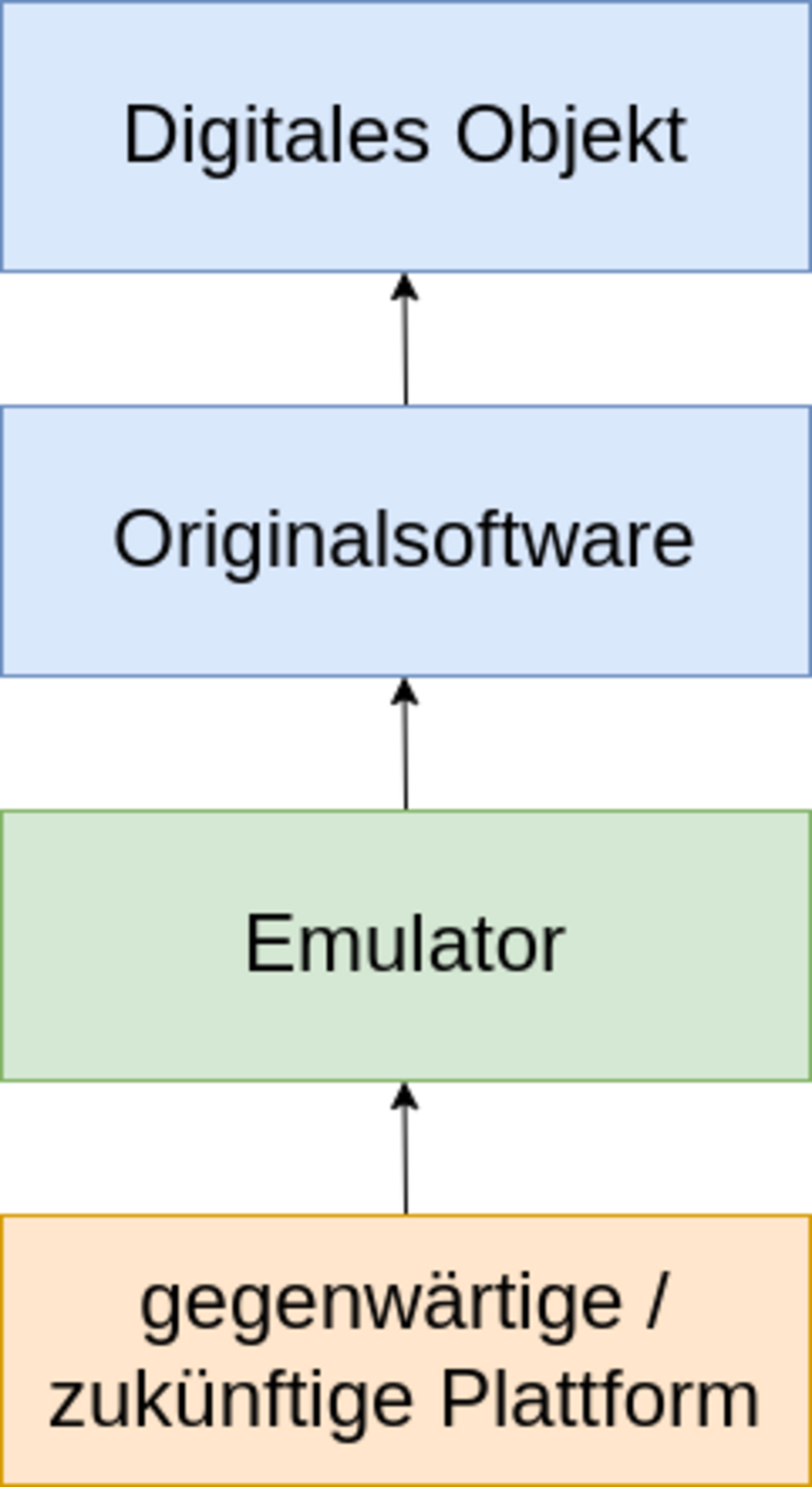
Im Gegensatz zu "klassischen" Medien reicht es nicht aus, die Datenträger zu erhalten. Technische Systeme und Konzepte sind erforderlich, um die Daten zu interpretieren. Digitale Informationen veralten mit der Umgebung, in der sie erstellt wurden. Daraus ergeben sich Abhängigkeiten von
In der digitalen LZA haben sich aus diesem Grund zwei Konzepte ergeben:
In diesem Ansatz verhalten sich zukünftige Technologien wie die Originalumgebung des digitalen Objekts. Der Originaldatenstrom kann in ursprünglicher Form zugänglich gemacht werden. Der Nachteil: Diese Methode ist sehr aufwändig, da auch die Emulationsumgebung ständig an neue Umgebungen angepasst werden muss.
Bei der Migration handelt es sich um die Transformation eines digitalen Objekts in anderes Format, um der sogenannten Formatobsoleszenz vorzubeugen. Dabei wird das Objekt verändert und an seine neue Umgebung angepasst, um zukünftigen (sich ebenfalls verändernden) Nutzungsansprüchen gerecht zu werden. Diese Methode ist aufgrund ihrer – im Vergleich zur Emulation – „einfacheren“ Umsetzbarkeit in der aktuellen LZA weiter verbreitet. Der Nachteil wurde bereits angesprochen: Digitale Dateien (Originale) werden im Laufe der Zeit transformiert / verändert.
Aus archivarischer Sicht müssen aus diesem Grund Fragen nach der Authentizität des digitalen Objektes sowie einer engmaschigen Qualitätskontrolle (Identifizierung / Validierung) in den Blick genommen werden.

In der digitalen Langzeitarchivierung spielen deshalb die Formatidentifizierung und anschließende Validierung eine entscheidende Rolle. Das korrekte Identifizieren und Kategorisieren von Dateiformaten sind von großer Bedeutung, um langfristig Authentizität, eine sichere Aufbewahrung und Zugänglichkeit von digitalen Dokumenten und Daten zu gewährleisten.
Ein erstes wichtiges Merkmal ist die Dateiendung. Eine Buchstabenkombination am Ende des Dateinamens, zum Beispiel “.jpg” für eine Bilddatei oder “.pdf” für ein PDF-Dokument. Die Dateiendung kann einen Hinweis auf das Format geben, ist aber nicht immer zuverlässig, da sie leicht geändert oder falsch angegeben werden kann.
Aus diesem Grund erfolgt die Erkennung des Dateiformates aufgrund spezifischer Merkmale und Muster die sich auf Code-Ebene in der Datei befinden. Diese eindeutigen Muster von Dateiformaten werden auch „Signaturen“ genannt und sind in einer internationalen Datenbank hinterlegt. Das Dateiformatregister PRONOM8 wird von den National Archives in England gepflegt und kann dort mit den passenden Tools abgefragt werden.
So komplex die Abläufe dieser systemimmanenten Prozesse im Detail sind, so nachvollziehbar sind in vielen Workflowmodellen (Preservation plans) die Konsequenzen einer fehlerhaften Formatidentifizierung und -validierung.
Für Daten, die aus der Webarchivierung in ein Langzeitarchivierungssystem kommen, sind die eben erwähnten Abläufe nicht anwendbar, da bereits veröffentlichte Inhalte im Web, nachträglich nicht korrigiert werden können. Jede Änderung an einer Webseite führt zu einer erneuten Veröffentlichung und erzeugt im Webarchiv einen neuen Zeitschnitt. Obwohl es Empfehlungen gibt, wie Webseiten archivierungsfreundlich gestaltet werden sollten9, können Medieninhaber*innen nicht dazu verpflichtet werden, Standards, Richtlinien und bestimmte Formate zu verwenden.
Eine Migration eines einzelnen Dateiformates im archivierten Web hätte weitreichende Auswirkungen auf den Inhalt anderer Objekte, die dann ebenfalls migriert werden müssten. Das grundlegende Prinzip der Hyperlink-Fähigkeit des Webs würde beispielsweise bedeuten, dass bei einer Migration aller „.gif“ zu „.png“ Dateien auch alle HTML-Dateien angepasst werden müssten, die auf solche Dateien verweisen.
Es gibt jedoch Systeme, die für solche Fälle eine sogenannte „Migration on demand“ durchführen können, bei der das LZA-System ein als veraltet gekennzeichnetes Dateiformat beim Abruf in das aktuellste Format umwandelt und der Browser die Daten dieses Formates für die Anzeige der Ausgangsseite nutzt.10
Allerdings scheint angesichts der Vielzahl unterschiedlicher Dateiformate, die in Webarchiven vorhanden sind, eine Migration als keine geeignete Strategie für die Langzeitarchivierung. Im Webarchiv Österreich konnten aktuell aus allen archivierten Objekten 553 unterschiedliche Datei-Signaturen identifiziert werden. Beispielsweise ist das für das Web essentielle HTML-Format derzeit in der PRONOM-Datenbank in sieben verschiedenen Formatversionen und weiteren drei Versionen ohne Angabe einer Versionsnummer vorhanden.

Durch die Analyse sämtlicher identifizierbarer HTML-Seiten aus den vergangenen zehn Domain-Crawls von 2009 bis 202211 wird deutlich sichtbar, wie erfolgreich sich das aktuelle HTML 5-Format etabliert hat, während die Versionen 4.0 und 3.2 in den letzten Jahren praktisch kaum noch anzutreffen sind.
In den letzten Jahren blieb aber der Prozentsatz der HTML-Seiten, die aufgrund fehlender Merkmale keiner spezifischen Version zugeordnet werden können, auch stabil.
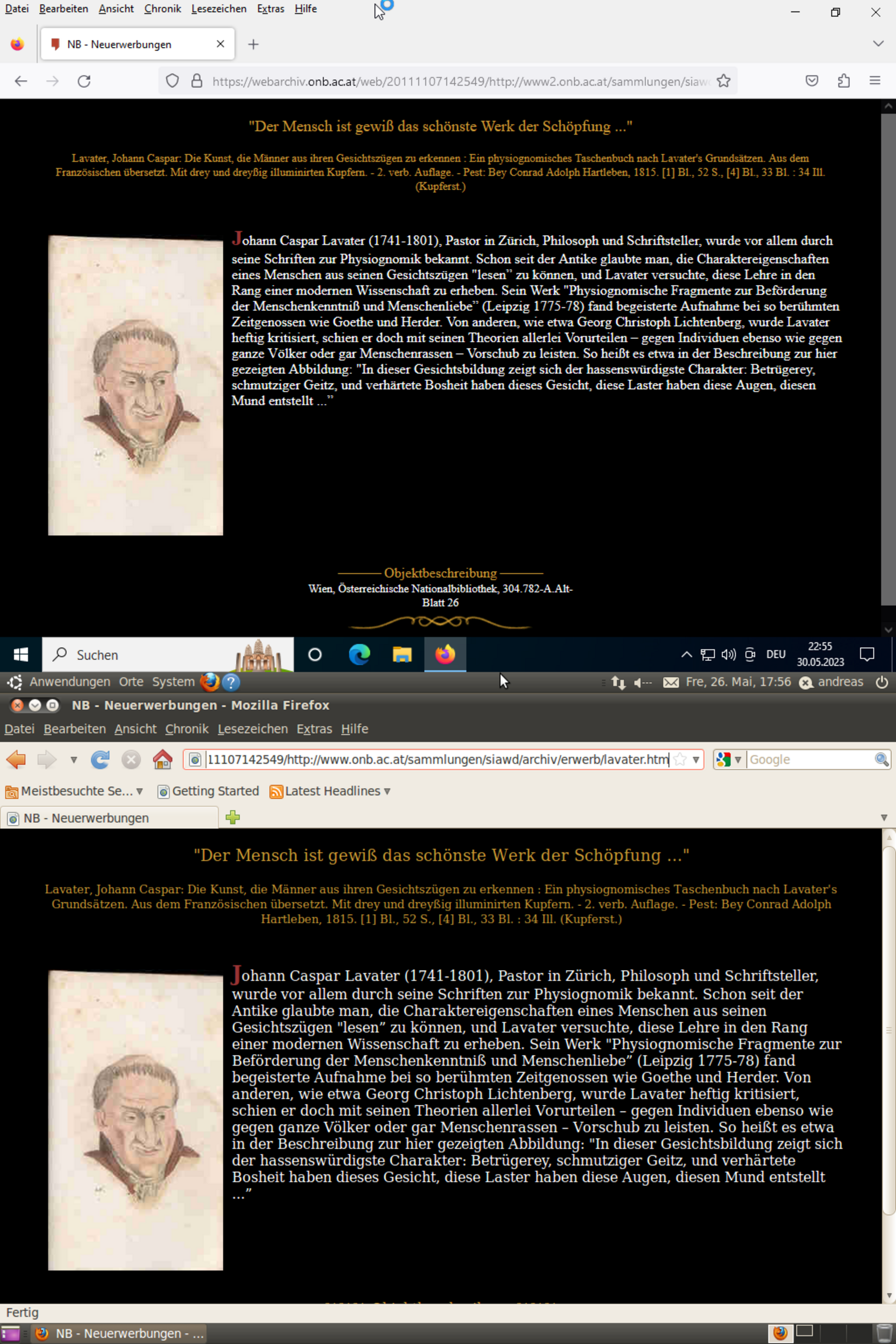
Wenn wir einzelne archivierte Webseiten in den verschiedenen erwähnten Versionen mit einem modernen Browser betrachten, wird offensichtlich, dass moderne Browser schon eine bedeutende Aufgabe der Emulation übernehmen und in der Lage sind, verschiedene, zum Teil veraltete Formate darzustellen.
Die Frage, ob Migration oder Emulation die bessere Lösung für die Langzeitarchivierung darstellen, bleibt nach wie vor offen. Derzeit ist es sinnvoll, die Strategie je nach Anwendungsfall zu wählen. Aufgrund der Tatsache, dass das Emulieren von Software, Betriebssystemen und Hardware wesentlich einfacher geworden ist und viele dieser Funktionen heutzutage problemlos vom Browser ausgeführt werden können, wird der Browser in Zukunft eine immer wichtigere Rolle in der Langzeitarchivierung spielen.
Die Österreichische Nationalbibliothek bedankt sich sehr herzlich beim Wiener Städtische Versicherungsverein für die Unterstützung des Webarchivs Österreich.
Über die AutorInnen: Karin Heide ist Projektverantwortliche für digitale Langzeitarchivierung an der Österreichischen Nationalbibliothek, Andreas Predikaka ist technisch Verantwortlicher des Webarchivs Österreich an der Österreichischen Nationalbibliothek.
1 Liegmann, Hans, Nestor Handbuch: Eine kleine Enzyklopädie der digitalen Langzeitarchivierung, Einführung, [online] urn:nbn:de:0008-2010071949 [31.05.2023]
3 Eines der ersten bedeutenden Projekte auf dem Gebiet der digitalen Langzeitarchivierung war das "Electronic Recording Machine, Accounting" (ERMA)-System, das in den 1950er Jahren von der Bank of America entwickelt wurde. Dabei handelte es sich um ein computergestütztes System zur Verarbeitung von Scheckzahlungen.
4 Beispielhaft erwähnt sei hier das Projekt „Digital Sky Survey“ (DSS), das in den 1980er Jahren startete und zum Ziel hatte, die gesamte Himmelsdurchmusterung in digitaler Form zu erfassen und zu archivieren. Dabei wurden alte fotografische Platten und Dias astronomischer Aufnahmen gescannt und digitalisiert. Die DSS bildete die Grundlage für spätere digitale Himmelskarten und ermöglichte die systematische Archivierung und den einfachen Zugriff auf astronomische Beobachtungsdaten. Die erste Version des DSS wurde 1994 auf 102 CDs veröffentlicht. [online] https://en.wikipedia.org/wiki/Digitized_Sky_Survey [31.05.2023]
5 "Das als ISO 14721:12 verabschiedete Referenzmodell `Open Archival Information System – OAIS` beschreibt ein digitales Langzeitarchiv als eine Organisation, in dem Menschen und Systeme mit der Aufgabenstellung zusammenwirken, digitale Informationen dauerhaft über einen langen Zeitraum zu erhalten und einer definierten Nutzerschaft verfügbar zu machen.“ Brübach, Nils, Das Referenz Modell OAIS in: Nestor Handbuch: Eine kleine Enzyklopädie der digitalen Langzeitarchivierung, [online] urn:nbn:de:0008-2010061762 [31.05.2023]. Siehe auch: [online] http://www.oais.info [31.05.2023]
6 Vlaeminck, Sven, Nestor Handbuch: Eine kleine Enzyklopädie der digitalen Langzeitarchivierung, Organisation, [online] urn:nbn:de:0008-20100624144 [31.05.2023]
7 Die Zertifizierung als vertrauenswürdiges Langzeitarchiv setzt die Implementierung des OAIS-Referenzmodells voraus. Mittlerweile haben sich drei Verfahren etabliert, die die Umsetzung des funktionalen OAIS-Modells überprüfen: CoreTrustSeal (CTS) [online] https://www.coretrustseal.org [31.05.2023], nestor Siegel/DIN 31644 [online] https://www.langzeitarchivierung.de/Webs/nestor/DE/Arbeitsgruppen/AG_Zertifizierung/ag_zertifizierung.html [31.05.2023], ISO 31644 [online] http://www.iso16363.org [31.05.2023]
8 Neubauer, Mathias, Extraktion, technische Metadaten und Tools in: Nestor Handbuch: Eine kleine Enzyklopädie der digitalen Langzeitarchivierung, [online] urn:nbn:de:0008-20100617150 [31.05.2023]
9 [online] https://www.nationalarchives.gov.uk/aboutapps/pronom/default.htm [31.05.2023]
10 Empfehlung der Library of Congress zur Erstellung archivierungsfreundlicher Webseiten: [online] https://web.archive.org/web/20221020184535/https://www.loc.gov/programs/web-archiving/for-site-owners/creating-preservable-websites/ [31.05.2023]
11 Vgl. Brown, Adrian (2006): Archiving websites : a practical guide for information management professionals, London: Facet Publ., 97f
12 Für die Analyse wurden von jedem Domain-Crawl sämtliche erfolgreich identifizierten HTML-Dateien der ersten Stufe (Crawl jeder Domain bis zu einer Größe von 10 MB) herangezogen. Vgl. : Predikaka, Andreas (2020): "Wie das österreichische Web im Archiv landet", [online] https://www.onb.ac.at/mehr/blogs/detail/wie-das-oesterreichische-web-im-archiv-landet-3 [08.08.2023]
Aufgrund von Veranstaltungen wird der Prunksaal am Donnerstag, 24. Oktober bereits um 18 Uhr, am Freitag, 1. November bereits um 16 Uhr und am Donnerstag, 14. November bereits um 18 Uhr geschlossen.
Die Lesesäle am Heldenplatz bleiben am Samstag, den 2. November, geschlossen.